DUPR Made Me Do It: How Score Differential Affects Your Pickleball Rating
Score differential is back at DUPR. Ratings can rise after losses and fall after wins. We stay positive at Palmera, with a wink at DUPR's quirks, and break down what it means for your game.

- DUPR now adjusts ratings by expected score differential, not just wins and losses. You can go up after a loss or down after a win.
- Bracket gravity pulls you toward the division mean unless you consistently beat the expected spread.
- The model incentivizes blowouts, especially when you’re the favorite.
- “Poison DUPR” entrants (players underrated on paper) can send shockwaves through a draw.
- DUPR may exclude lopsided‑expected matches from rating updates. I consider that lazy data science.
- DUPR Forecast now exposes favorites, underdogs, and predicted scores before you play.
- Score differential has merit, but it should be a weighted factor, not the only factor in standard scoring.
You are not your DUPR.
What “score differential” means in practice
Every match has an expected score derived from current ratings. DUPR identifies the favorite and the underdog, then predicts a margin and expected points.
Example: If DUPR expects 11–3 but the favorite wins 11–8, the favorite may lose rating points (underperformed versus expectation), and the underdog may gain rating points (outperformed expectation). DUPR’s help center provides more examples along these lines.
On‑court takeaways (from recent DUPR‑rated events)
Before we go further: you are not your DUPR. Ratings can gatekeep brackets, so I get that they matter. But for most players, DUPR remains far from accurate, and in practice you shouldn’t obsess over it.
Here are my observations and thoughts after competing in two events rated by the updated DUPR algorithm:
1) Bracket gravity is real
Whatever backet you are in, expect to be pulled toward the bracket's middle. Let's say you're in the 4.0 bracket (against mostly ≈3.7–4.3 opponents) and trade wins and losses therein, you should certainly expect your rating to be pulled toward the backet's middle ~4.0. If you start winning big, your rating climbs, but DUPR then expects bigger spreads from you. Unless you consistently beat the expected spread versus similar ratings, the bracket’s ambient tug recenters you. Think rating inertia created by constant, same‑tier competition. Competing a bracket higher means you will likely be the underdog in most of your matches for a time, with rating inertia pulling you up despite losing matches (so long as you outperform DUPR's predicted underdog scores in your games). However, some players have found it incredibly difficult to move their ratings, so they have taken to creating a new DUPR account to break free from prior bracket gravity. Regardless, whatever bracket you are in, the current algorithm design pulls everyone to the median of the bracket's ratings.
2) Better make it a beatdown
Nico the Lefty's Instagram post captures the mindset shift: https://www.instagram.com/p/DMWYZDNv5yT
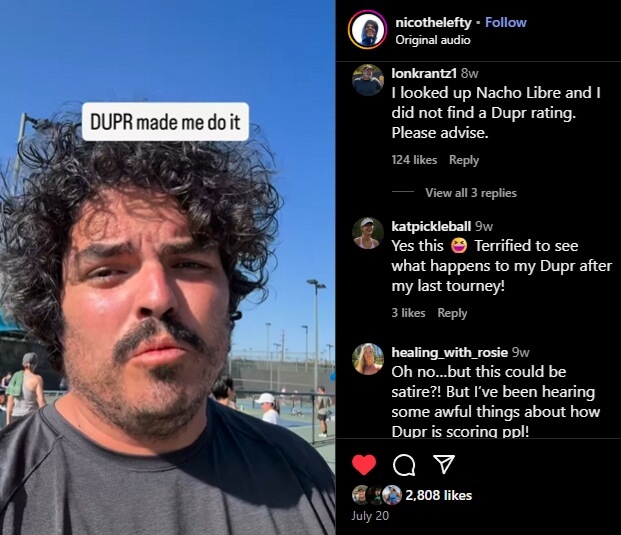
Scouting the opponent’s DUPR beforehand, this pickleballer realized the algorithm would punish a narrow win against a lower‑rated team, so he and his partner went full send. Algorithms shape behavior; here, a player who might normally take it easy instead pushes extra hard to run up the score, lest DUPR lower their rating for "underperforming." #DUPRMadeMeDoIt
3) “Poison DUPR” shockwaves
Similarly, let's now consider the underdog with a mismatched low rating, say a listed 4.2 entering a 5.0 event after serious training gains. Because DUPR evaluates performance vs. expected score, that 4.2 can gain heavily even in losses if they just outscore the prediction. Meanwhile, legit 5.0s who win without covering the spread get nicked. A couple of these entrants in an event can distort hard-earned ratings across the draw simply by a player with an inaccurate DUPR outperforming arbitrary low expectations, even while losing matches!
But wait: the score may not affect your DUPR rating
DUPR states that when there’s a large rating gap, the match may be excluded from rating updates. According to DUPR logic, the expected outcome is so lopsided that even a decisive win can register as “underperforming,” so the match is not rated.
Hot take: This is lazy data science.
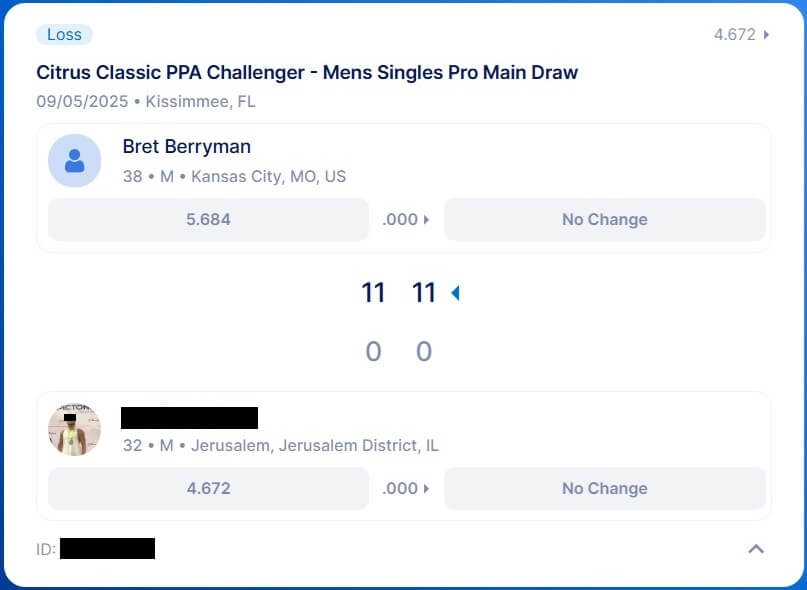
I saw this at the Citrus Classic more than once. Example: a 4.672 singles player entered pro men’s singles against Bret Berryman (5.684) and was double‑pickled. Neither rating moved. DUPR predicted a lopsided score, so the match was unrated, and in this particular case, DUPR's prediction was accurate.
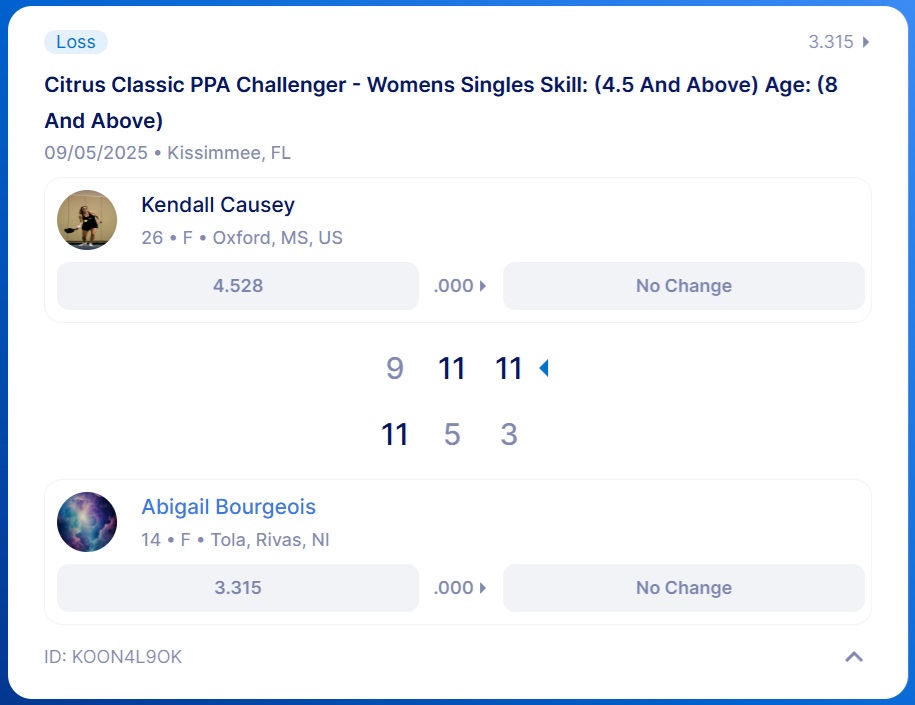
But what if DUPR predicts a blowout and the match becomes a battle? (This is where the "lazy data science" comes into perspective.) In Abigail’s first women’s 4.5 singles match, DUPR flagged it as lopsided in advance because her 3.3 rating was up against a 4.5 rated opponent. Abigail, currently a 3.1 in singles per DUPR, won the first game and totaled 19 points against a 4.5, but ultimately lost the match. Because the system had pre‑labeled it "lopsided" and DUPR precludes such predicted matches from any further analysis, the actual outperformance by Abigail is data excluded from the algorithm. This is lazy programming.
When a model ignores real outperformance, it stops measuring reality and starts defending itself.
One would expect any clearly competitive match to be factored by the algorithm. One would think that if an underdog beats the prediction (no matter how ugly the prediction or how much of an underdog someone is), some rating credit should accrue. Hopefully, DUPR fixes this.
Abigail now faces a funny situation: By all measures other than her DUPR, 4.5 singles is the most appropriate bracket for her given her actual level of play. But given her sub-3.5 rating for singles, any matches against 4.5 players won't be rated, so her DUPR is essentially stuck unless she conforms to her rating with bracket entry. My guess is she'll not let the algorithm determine her personal development trajectory, so it'll be funny to see her eventually log wins at the 4.5 level while DUPR maintains that she's below 3.5.
DUPR doubles down with DUPR Forecast
DUPR’s Forecast lets you see, before you play, who is the favorite and who is the underdog, plus what score you must outperform to go up. Through year‑end, you can simulate matchups with different partners and opponents. (I expect this simulation feature to be priced in 2026.)
If you ask me, the last thing you should worry about in a tournament is an arbitrary rating. Again: you are not your DUPR. Why not just go into every match focused on bringing your best performance? And be centered on whatever it is that best enables your flow state. Maybe for some people, seeing what DUPR predicts about your upcoming match is a great way to get dialed in, but I expect that for most people, obsessing over ratings and score predictions before a match is probably more likely to throw off your mental game heading in.
Conclusion: DUPR score differential and pickleball ratings
Do you think Ben Johns or Anna Leigh Waters are checking DUPR before or after matches? Is Andrei Daescu running simulations to see if he is favored? I know for a fact Ben doesn’t care, and neither should we.
We do need a rating system. If you’re grinding tournaments, DUPR gets enough data that its outputs for serious players are probably usable. But if you compete infrequently, the model lacks signal, and bracket gravity plus lopsided‑prediction exclusions can trap you in odd places.
I see the value of score differential, but as a weighted input, not the sole driver. The 100% differential approach fits rally scoring better. With most DUPR‑rated events using standard scoring, there is ample room to make the algorithm smarter.
Glossary
- Expected spread: The margin DUPR predicts you should win by.
- Bracket gravity: The tendency of repeated, same‑tier competition to pull your rating toward the division’s mean unless you consistently exceed expected spreads.
- Poison DUPR: A mismatched, underrated entrant whose outperformance distorts rating adjustments across a draw.
Let's Connect



%20We%20played%204.webp)


